Warning: this post is mostly wild speculation, although there is some evidence in here.
Bing has launched a Twitter search engine (there’s coverage here on Search Engine Land) – it lets you search tweets. (Update: Google has too.)
What I’ve been wondering since last week is whether Google is already using signals from either Twitter or URL shorteners as part of its ranking decisions. You could see why it want to – seeing which pages people are retweeting and passing around on Twitter would help it work out which pages are relevant for ‘newsy’ search terms (those where there is a big surge in searches for particular keywords).
Would this explain why one of my blog posts with few tweets was ignored – but a similar, slightly later one with 00s of tweets jumped into the top 10 results?
The evidence
Testing such a thing would be a nightmare – how could you set up 2 different, but similar, pages and get loads of people to tweet one and not the other?
But I accidentally did something pretty close to that when the Jan Moir affair erupted last Friday.
On that Friday, I wrote two posts:
- Jan Moir: Mail readers reject her hateful bile (probably) – published at 11.23am. This was retweeted 9 times.
- Jan Moir: Twitter forces Mail to pull all adverts – published at 2.45pm. This was retweeted 345 times.
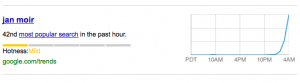
Jan Moir: hot (as a search term
As the Jan Moir affair grew, ‘Jan Moir’ hit the top of the Twitter trend list, and more and more people searched, tweeted and wrote news stories and blog posts about her. At 2.45pm I noticed that searching for ‘Jan Moir’ triggered the hotness graph in the Google results, revealing it was the 42nd most popular search in the previous hour.
During all this, my first post was largely ignored by Google – it wasn’t in the top 50 results for a search on ‘Jan Moir’. I was a bit surprised by this – my blog usually does fairly well straightaway for posts obviously related to newsy keywords. (And non newsy ones – 19 minutes after publishing this post, for instance, I rank 5th for a search on ‘Google signals Twitter’, not that there’s much competition for that search term!)
The second post, however, was retweeted straightaway many, many times. And by 4pm, just an hour later, it was the 7th result for a search on ‘Jan Moir’.
Both posts were about Jan Moir. Both had ‘Jan Moir’ at the front of the title. Yet one was ignored by Google, and the other appeared in the top 10 results. Over the weekend, the 2nd advert-related one appeared as high as 5, and as a number of people linked to it, it settled down at position 11, which is where it is today.
So did Google decide the first post wasn’t worth a high ranking amongst all the pages being written about Jan Moir – but decided the second was – well before there were any web links to it – because of the volume of tweets about it?
The caveats
There are all sorts of other reasons this might be complete and utter rubbish.
- Maybe Google was using some other data (EG Google Analytics) to decide what was relevant (but visitor numbers are a bit circular / self-fulfilling as a relevance metric – and I’ve not seen anyone suggest that visits to a page are an important ranking factor).
- It could just be coincidence.
- Perhaps Google only decided the search term ‘Jan Moir’ was ‘newsy’ quite late in the day, and decided to promote blog posts in the rankings only from that point. So the first post missed any QDF boost. Jan Moir tweets, according to Trendistic, really went hot at about 9-10am, peaked at noon, and only started to decline at 5pm. But who knows when search volumes picked up …
What do you think? (If you’ve read this far and you’re a Sphinn member, why not vote it up at Sphinn?)
You might also like
- Is the new retweet the end of angry Twitter mobs?
- Does Google edit swear words from the results of popular searches – or is it doing Jan Moir a favour?
- Twitter’s latest SEO improvement: meta descriptions
- New Wikio rankings for Online Marketing section
- Twitter’s appearance in Google: sort it out …
Leave a comment!